Elemezzük a következő mondatot: Meg akartalak ölelni.!
A szabályalapú elemzés lépései a következők:
-
Megkeressük az állítmányt (ragozott igeként azonosítható alak a lexikonból = akartalak).
-
Megkeressük a lehetséges vonzatokat (akar ige vonzata lehet egy tárgyesetű főnév vagy egy főnévi igenév).
-
A meg lehet kötőszó vagy az ölelni főnévi igenév igekötője. Ha kötőszó, akkor az akar ige elé kellene valami, mert nem szeret hangsúlyos lenni (Pl.: Meg (még) ölelni is akartalak.).
-
Mivel nincs az akar ige előtt hangsúlyhordozó, ezért a hangsúlyt csak a meg hordozhatja, akkor pedig igekötő.
-
Tehát a mondatban szereplő vizsgálandó szavak: akar + megölelni.
A statisztikai elemzés lépései a következők:
-
Megkeressük az állítmányt (ragozott igeként azonosítható alak a lexikonból = akartalak).
-
Egy olyan szósorban, ahol a meg után az akar ige ragozott alakja következik, utána pedig egy főnévi igenév, az esetek igen magas százalékában a meg a főnévi igenév igekötője.
-
Tehát a mondatban szereplő vizsgálandó szavak: akar + megölelni.
A statisztikai elemzés második lépése természetesen sok előkészítést igényel. Először is kell egy korpusz, aminek egy részét kézzel annotálják. A korpusz egy hatalmas digitális szöveggyűjtemény, az annotálás pedig azt jelenti, hogy valakik, akik értenek az elemzésekhez, beírják a szöveg szavai mellé, hogy az milyen szófajú, mi a szótöve és milyen toldalékok vannak rajta. Ezután elindítanak rá egy tanulóalgoritmust (egy programot), ami az annotált szövegrészből statisztikai szabályokat állít elő és ennek alapján annotálja a szöveggyűjtemény még érintetlen részét. A géppel annotált szövegrészleteket ismét szakértők ellenőrzik, és finomítják, javítják a tanulóalgoritmust. Mostanra a nyelvészeti tanulóalgoritmusok annyira tökéletesek, hogy a gépi annotálású szövegek ugyanolyan arányban megfelelőek, mint a nyelvészek által annotáltak (95% felett! igen, a nyelvészek annotálása sem 100%-os).
Hasonlítsuk össze a két módszert, a szabályalapút és a statisztikait!
-
A statisztikai módszer sokkal gyorsabb.
-
A statisztikai módszerhez nagyon sok szöveg elemzését, vizsgálatát el kell előbb végezni, hogy meglegyenek a sémáink (korpusznyelvészet).
-
A statisztikai módszer a Meg (még) ölelni (is) akartalak. mondatban is azt feltételezné, hogy a két keresett szó az akar és a megölelni, holott itt ez nem lenne igaz! Hiszen ebben a mondatban a meg (kötőszó), az akar (ige) és az ölelni (főnévi igenév) szavak szerepelnek.
Vagyis a statisztikai sokkal gyorsabb, és sok, még a nyelvészek számára is meglepő összefüggést is feltárhat, viszont a ritkább esetekben biztosan hibázni fog. A szabályalapú lassabb, nehézkesebb, de ha kicsiszolódtak a szabályok, soha nem hibázik. Viszont soha nem is jön rá új összefüggésekre. A memóriája, valamint a sebessége azonban sokszorosa az emberinek.
Ha hasonlatot akarnánk keresni arra, hogy hogyan érdemes elképzelni a számítógépes programok működését, valami olyasmit mondhatnánk, hogy olyanok, mint a gólemek Pratchett regényeiben (pl.: Agyaglábak). „Az átok izék csak akkor hagyják abba a munkát, ha kifogytak a tennivalóból. Néha még akkor sem, ha a szóbeszédnek hinni lehetett. Az ember olykor hallott történeteket arról, hogy valamelyik gólem eláztatta az egész házat, mert csak azt mondták neki, hozzon be vizet a kútról, de azt nem, hogy most már elég. Vagy hogy addig mosogatták az edényeket, amíg azok papírvékonyságúakra nem koptak. Az agyatlan ostobái. Igaz, ha az ember szemmel tartotta őket, igencsak hasznossá tudták tenni magukat.” (Pratchett 2010: 149-150. oldal)
A számítógépek számára a tennivalót (legyen az akár valamilyen nyelvészeti feladat, mint a helyesírás-ellenőrzés, fordítás, felolvasás) algoritmusokban érdemes megfogalmazni. Hogyan is néznek ki az algoritmusok? Elképzelhetjük őket, mint olyan folyamatábrákat, amelyekben mindig egyértelmű, hogy melyik utasítássort kell éppen végrehajtani, és mindig van a cselekvéssornak jól definiált vége.
Álljon itt példaként egy főzésnek a folyamatábrája (készítette: Kovács Tímea, 2011, PTE BTK Nyelvtudományi Tanszék):
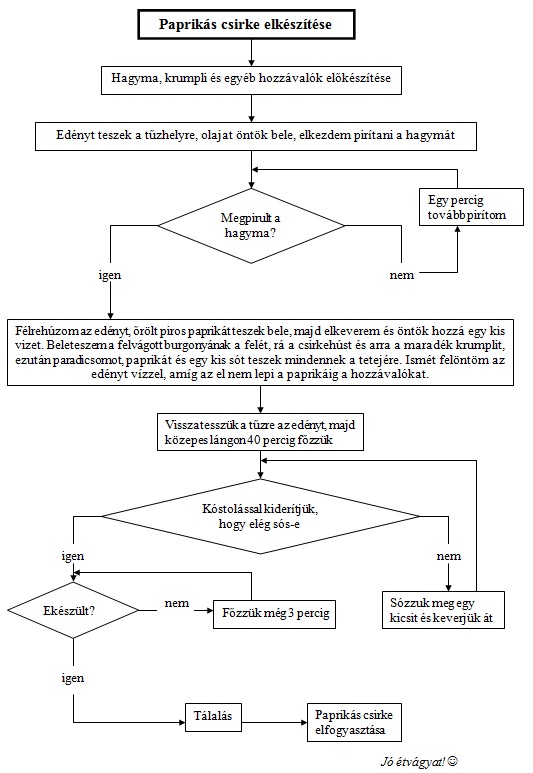
1. ábra: folyamatábra
A nyelvészeti elemzéseket ilyen egyértelmű lépésekre és pontosan megválaszolható eldöntendő kérdésekre kell felbontanunk ahhoz, hogy egy számítógép számára megfogalmazhassuk őket. A jól definiált elemzések végrehajtásában ezután a program már nem fog hibázni.
Hogy ne keseredjünk el a számítógép tökéletessége és az emberi elme lassúsága miatt, olvassuk el Nádasdy írását a fiatal informánsok nyelvtudásáról!