3.10. Fordítás számítógéppel
12. FELADAT
A 3) vizsgálatban gépi fordítások eredményeit kellett vizsgálni, összehasonlítani. Mik a tapasztalatok?
Ma már triviális a nyelvtechnológusok számára, hogy nem érdemes a közeljövőben automatikus gépi fordításra törekedni. A cél az emberi fordítás gépi támogatása: azaz a szótárazás segítése, az ismétlődő szerkezetek előfordítása, a szinonimák közötti választás segítése.
13. FELADAT
A 4a) vizsgálatban a digitális és a papírszótár előnyeit és hátrányait kellett összegyűjteni. Most idézzük fel ennek a vizsgálatnak az eredményét!
A digitális szótárak esetében a többszavas kifejezéseket mindegyik szavukra rákeresve meg lehet találni, míg a papírszótár mindig terjedelmi korlátokkal küzd, ezért a szerkesztőinek döntenie kell, hogy a többszavas kifejezéseket melyik szónál jeleníti meg. Ugyanakkor a papírszótár nagy előnye, hogy a szócikkek között vándorolhat a tekintetünk, és olyan összefüggésekre is rábukkanhatunk, amit a digitális szótárt használva nem veszünk észre, hiszen mindig csak egy szócikket látunk a monitoron. A digitális szótárak használatakor egyszerre több szótárban is kereshetünk, és a szótár „megfordítható”, azaz nem kell a két irányt (magyar-angol, angol-magyar) külön megszerkeszteni. A digitális szótár tárolhatja a toldalékolt alakokat is (kereshető formában), akkor is, ha azok szabályosan lettek létre hozva, a papírszótárban erre nem pazarolhatjuk a helyet. A digitális szótárhoz könnyen kapcsolható kiejtési (hangzó) szótár is. A digitális szótárak könnyebben elérhetőek, nem kell nagy papírköteteket cipelni, emelgetni, forgatni. És egy nagy előny: a digitális szótárak használatához nem kell tudni készségszinten az abc-t és a sorba rendezés szabályait!
A fordítócsoportok támogatására ma már nem csak egyszerű szótárak, hanem terminológiakezelő rendszerek, sőt fordítómemóriák is létrejöttek. A terminológiakezelő rendszerek azokat a szakkifejezéseket tárolják, amik a szövegben többször előfordulnak, ezzel segítve a következetes fordítást, akár egy fordító hosszabb munkájában, vagy több fordító közreműködése esetén. Ezek a szakkifejezések természetesen nem csak egy szóból állhatnak, lehetnek több szavas kifejezések, sőt, tagmondat szintű egységek is.
A fordítómemória lényege, hogy a fordítás során eltárolódnak a forrásnyelvi elemek és ezek célnyelvi megfelelőik, és ez egy későbbi fordítás esetén a fordító segítségére lehet. A fordítómemória csak akkor tud működni, ha megjelöljük, hogy melyik forrásnyelvi mondathoz melyik célnyelvi mondat tartozik. Jó példa erre a Biblia fordítás, ahol minden mondatot egy egyedi azonosító jelez az eredeti és a fordított szövegben egyaránt. Az automatizált szövegszinkronizálás során a számítógép önállóan találja meg az összetartozó mondatpárokat. Ebben nehézséget okozhat a mondatok azonosítása (egyrészt nem egyértelmű, hogy hol a mondat vége, másrészt lehet, hogy egy forrásnyelvi mondatnak a fordításban két mondat felel meg). A szegmentálásban fel lehet használni a már lefordított mondatokat pl. tulajdonnevek (kivéve a Duna – Danube, Bécs – Vienna típusú párokat), számok stb. megfeleltetésével. Formázott szövegek esetében a szegmensek elkülönítését elég bekezdésenként elvégezni (ez idő- és tárkímélőbb megoldás). A szöveg szinkronizálása, ahogy minden nyelvtechnológiai megoldás, lehet statisztikai (megadva egy hasonlósági mértéket) vagy nyelvészeti alapú.
A fordítómemóriát a fordítók munkájának segítése mellett szótár-kialakításra is lehet használni (lásd Prószéky - Kis 1999). Lássuk az alábbi mondatpárt:

- A példa forrása: Prószéky-Kis, 1999.
Ha nem ismerjük a password szó jelentését, de azt igen, hogy főnév, akkor öt lehetőség adódik a fordítómemória alapján a szótári tétel automatikus létrehozására (azaz öt szópár): password – másodperc, ablak, képernyő, felhasználó-azonosító, jelszó. Ha megvizsgáljuk a korpusz összes mondatát, és megszámoljuk, hogy hány olyan mondatpár van, amelyben előfordul a password – jelszó, password – ablak, password – másodperc stb. pár, és hány olyan, ahol ezek egymástól függetlenül fordulnak elő, akkor a legnagyobb valószínűséggel a password – jelszó jelentéspárt fogjuk kapni.
A fordítómemória tehát egy mondatpárokat tartalmazó adattárból áll, és egy olyan programrészből, ami a fordítandó szövegben megkeresi az adattárban szereplő mondatokat és felajánlja a fordításukat. Ez a megkeresés természetesen nem lehet karakterre pontos egyezés, hiszen kis különbségek (nevek, gépelési hibák stb.) lehetnek a tárolt változat és a most fordítandó mondat között. Fordítás során akkor ajánlhat a fordítandó mondatra egy verziót a program, ha a fordítandó mondathoz nagyon hasonlót talál az adatbázisban. A hasonlóságot felszíni értelemben kell érteni, azaz a karaktersorozatok hasonlóságát. Valójában ez nyelvészetileg nem igazán releváns, hiszen sokkal többet mondana a szerkezetek hasonlósága felszíni különbségük ellenére is.
A fordítómemóriának a sok előnye mellett néhány hátránya is van. Például az automatizált szövegszinkronizálás eredményezhet hibás párosításokat is, amelyek a későbbi fordítások során újra és újra felbukkanhatnak.

-
ábra: fordítómemória, 2. kép
Forrás: http://hunglish.hu/index.html.
Ingyenes párhuzamos korpuszok több helyen elérhetők a weben. Két angol-magyar párhuzamos korpuszt ajánlok:
1) http://corpus.nytud.hu/demo/infotrend/orwell/: Angol-magyar párhuzamos korpusz, Orwell: 1984 c. regénye alapján, az MTA Nyelvtudományi Intézetének Korpusznyelvészeti Osztálya hozta létre.
2) http://hunglish.hu/index.html: Hunglish korpusz, a BME Médiaoktató és Kutató Központ (MOKK) és az MTA Nyelvtudományi Intézetének együttműködése révén jött létre. 3,5millió mondatpárt tartalmaz, és mindenki tölthet fel bele dokumentumokat, bővítendő ezt a mondathalmazt. A feltöltött dokumentumok szűrésen esnek át, de azért természetesen most a tesztverzióban sok hibás adat is van a rendszerben, ahogy ez a fenti képen is látszik.
14. FELADAT
A 3) vizsgálat mondataiból válasszunk ki egy érdekesebb kifejezést, és vizsgáljuk meg, hogy a párhuzamos korpuszok (a fordítómemóriák potenciális alapjai) milyen megoldásokat javasolnak rájuk!

-
ábra: neck szó a párhuzamos korpuszokban
Forrás: http://corpus.nytud.hu/demo/infotrend/orwell/.
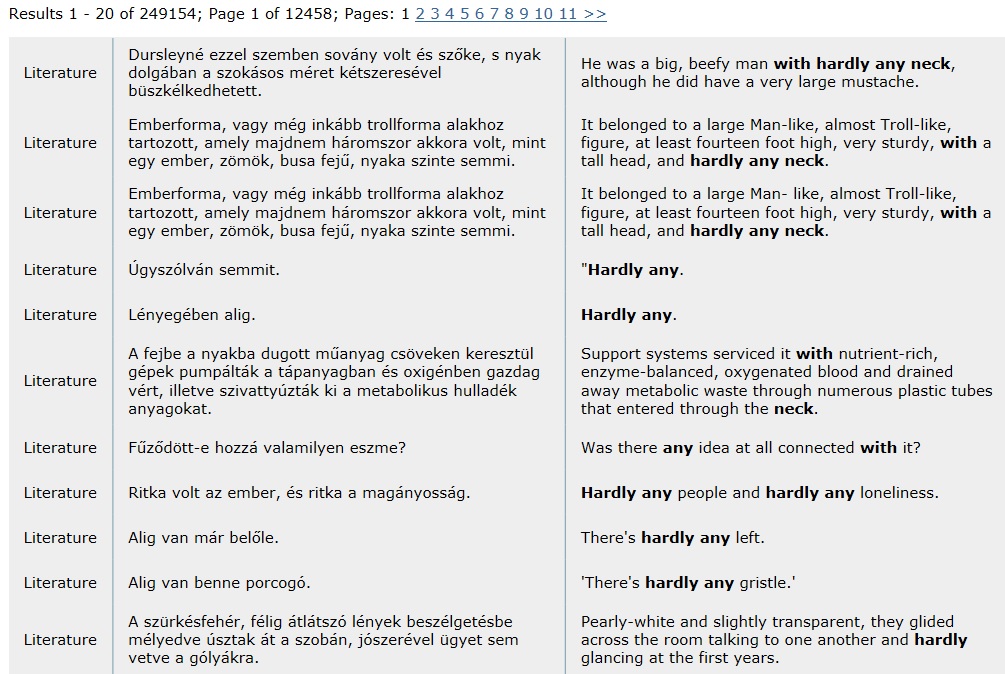
-
ábra: with hardly any neck kifejezés a párhuzamos korpuszokban
Forrás: http://hunglish.hu/index.html/.
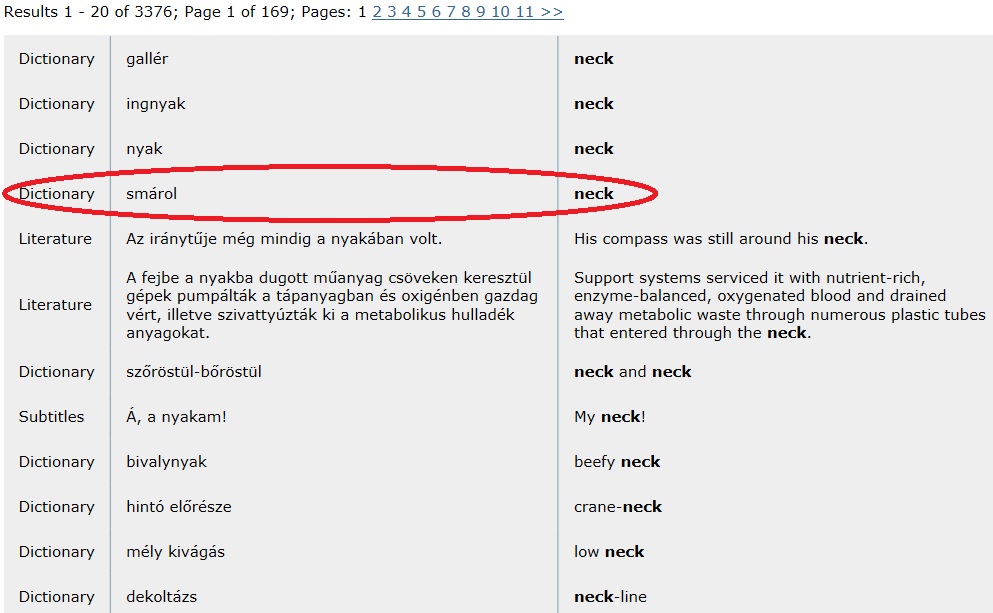
-
ábra: neck szó a párhuzamos korpuszokban
Forrás: http://hunglish.hu/index.html/.
15. FELADAT
Az új információk alapján vizsgáljuk meg ismét a 3) vizsgálat mondatait! Melyik típusú fordítóprogram készíthette őket? Milyen érvek szólnak az állítás mellett, és milyenek ellene?
A fordítóprogramok, ahogy más nyelvtechnológia alkalmazások, szinte minden esetben üzleti titoknak minősülnek. Ezért ritkán lehet pontos információt szerezni a működésükről. Kivétel ez alól, ha tisztán tudományos céllal, nem értékesítési céllal készül egy-egy fordítóprogram. Ilyenkor természetesen nincs pénz nagy korpusz építésére, komoly fejlesztőgárda foglalkoztatására, vagy akár fejlesztőeszközök beszerzésére. Kis adatbázis mellett a tisztán nyelvészeti fordítóprogramok is gyorsan és hibátlanul működnek. Példa erre a Gelexi-projekt, amelyben kb. százszavas szótáron villámgyorsan és hibátlanul működő fordítóprogramot tudott készíteni a tanszékünkön dolgozó nyelvészcsapat. Az a program szabályalapú és közvetett volt, mivel interlinguaként egy prolog-fordítás szolgált. E miatt a rendszer mindkét irányba (magyar-angol, angol-magyar) automatikusan működött, a két irány külön leprogramozása nélkül. Viszont az adatbázis méretének növelésével a program működése szélsőségesen lassult. Azóta számtalan kísérlet született az alapelvek megtartása mellett a fordítóprogram átdolgozására. További információk: http://lingua.btk.pte.hu/gelexi.asp