3.11. Keresés számítógéppel
Napjainkban a beszédfeldolgozás mellett a keresés a legfelkapottabb ága a nyelvtechnológiának. A keresés magába foglalja a szótárban való kereséstől az interneten történő hang- és képkeresésig mindent.
16. FELADAT
A 4a) és 4b) vizsgálatokban keresni kellett a számítógéppel. Egyik esetben szótárazni (4a), másik esetben könyvtári katalógusban keresni (4b). Foglalja össze a kétféle gépi-papír alapú keresés előnyeit és hátrányait!

-
ábra: szerelmeskedik szó a párhuzamos korpuszokban
Forrás: http://hunglish.hu/index.html/.
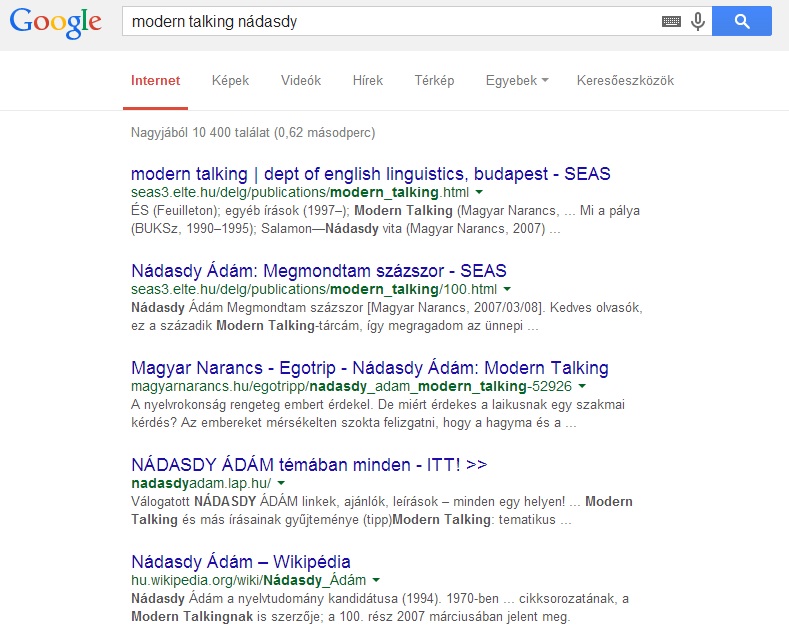
-
ábra: modern talking nádasdy keresőkifejezés
Forrás: Google
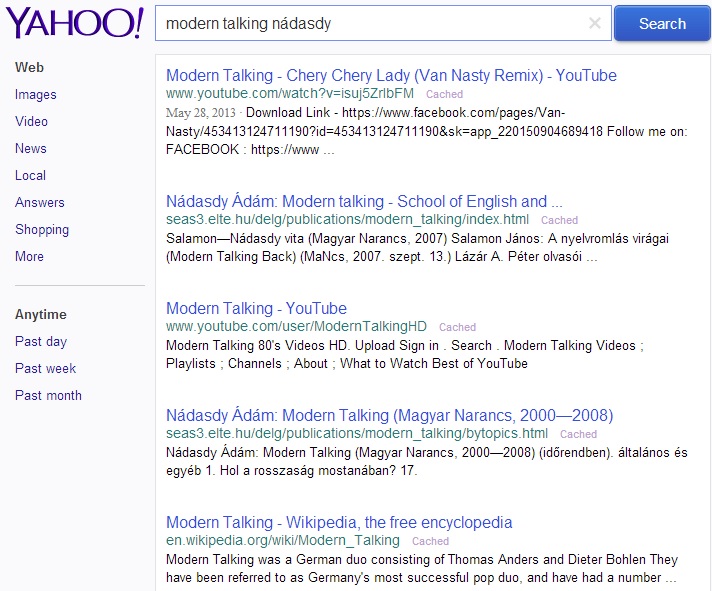
-
ábra: modern talking nádasdy keresőkifejezés
Forrás: Yahoo
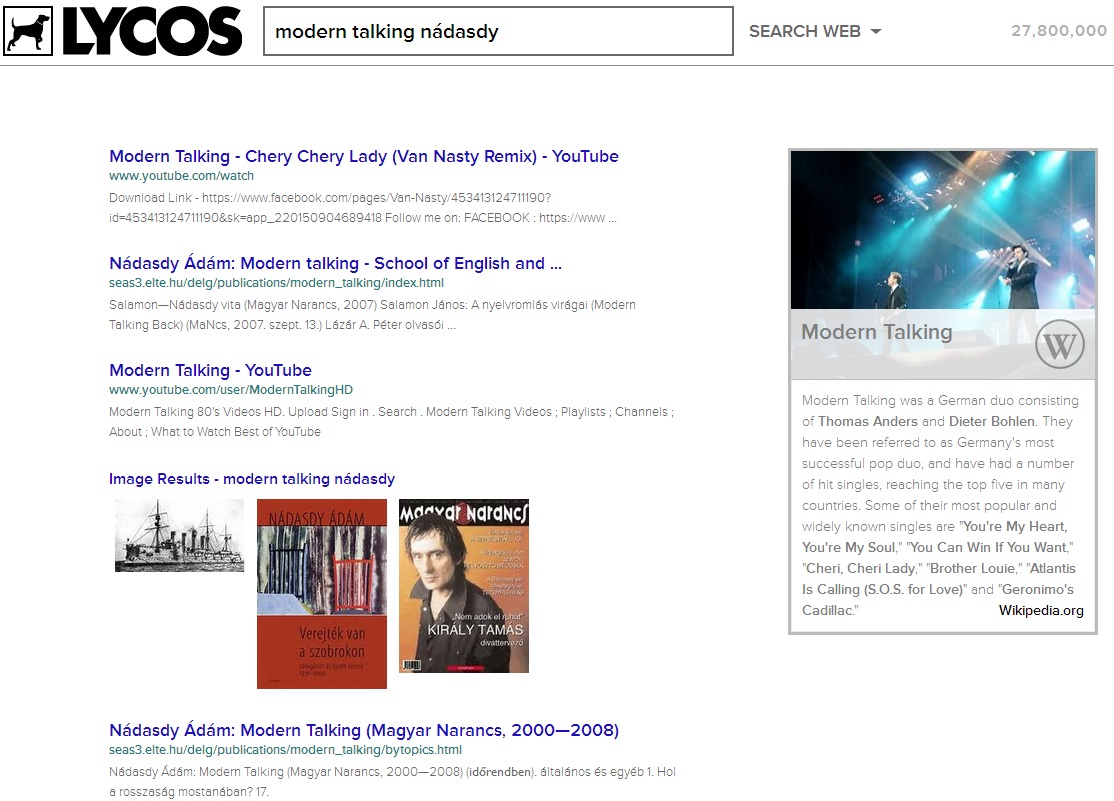
-
ábra: modern talking nádasdy keresőkifejezés
Forrás: Lycos
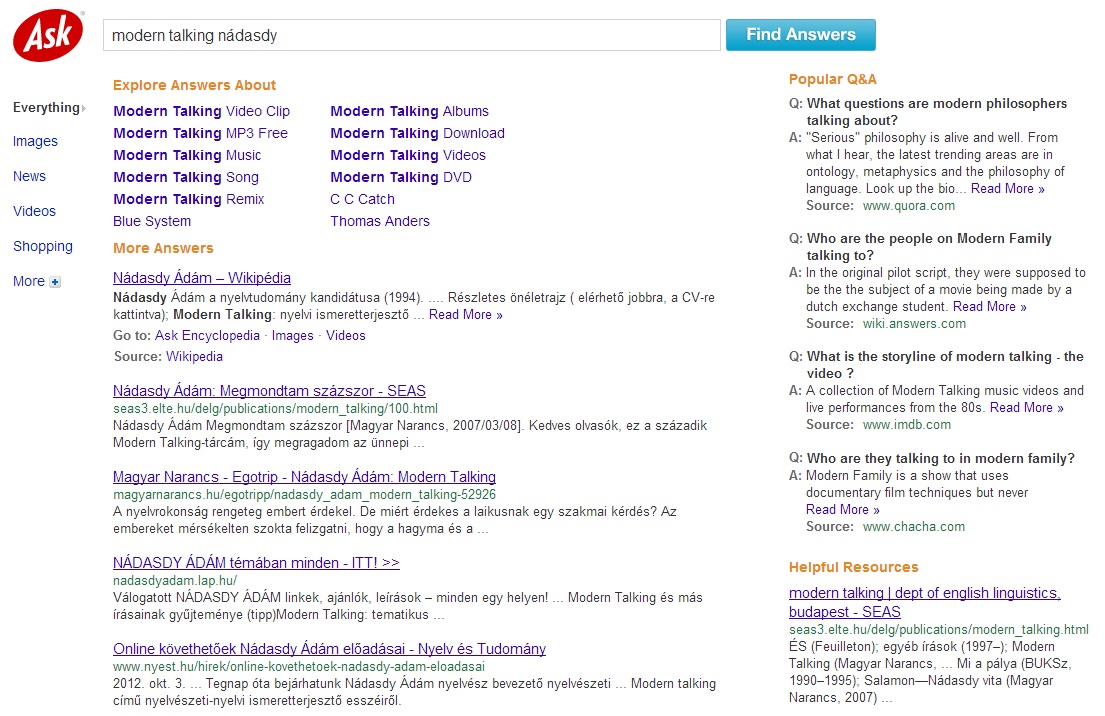
-
ábra: modern talking nádasdy keresőkifejezés
Forrás: AskJeeves
17. FELADAT
Foglalja össze a különböző webes keresők találati lista megjelenítő módszereit a fenti ábrák alapján!
A kereséseknél használt nyelvtan általában nem törekszik olyan pontos elemzésekre, mint amilyet a helyesírás-ellenőrzőkben használunk. Nagyon gyakran elegendő a szóból a nyelvre jellemző végződések levágása (pl: szerelmeskedik -> szerelmes), és utána a szónak a reguláris kifejezésekkel való mintaillesztése. Ilyen reguláris kifejezés pl. a - karakter. Ez azt jelenti, hogy a *-gal jelölhetjük, hogy a *-ot megelőző karakter tetszőleges számban fordul elő. Vagyis a gó*l kereső-kifejezésre a gól, góól, góóól is találat lesz. A következő ábrán a legalapvetőbb reguláris kifejezéseket mutatom meg, és kapcsolódik hozzá egy feladat is:
18. FELADAT
A következő ábra alján található email-cím ellenőrzési mintához írjon egy email-címet, amit jóváhagy a rendszer, és egyet, amit elutasít!

-
ábra: reguláris kifejezések Forrás: Bódis 2012.
A következőképpen fordíthatjuk le az email-cím ellenőrzési formát:
A sztring elején legalább egyszer (ezt jelenti a + jel) elő kell fordulnia egy karakternek, ami lehet A-Z közötti betű és 0-9 közötti szám, pont és aláhúzás (a [] között vannak felsorolva az alternatívák). Ezután jönnie kell egy @ jelnek. Aztán megint következik egy [] közé tett halmaz, amiből legalább egy karakternek szerepelnie kell. Ezek pedig: A-Z betűk, 1-9 számok, pont és kötőjel. Ezután következik egy pont. (A \. azt jelenti, hogy a pontot rendes karakternek kell tekinteni, nem vezérlőkarakternek.) A pont után jön egy min. két, max. 6 karakterből álló betűsor A-Z közötti betűkből. Ezzel a sztring véget ér.
Nos, milyen email-cím felel meg, és milyen nem a fent leírtaknak? Sikerült példákat találni? Jó lehet e szerint az ellenőrző minta szerint a kiss.maria@gmail.com? Vagy a kiss_maria@gmail.com? Vagy a kiss-maria@gmail.com? Ennek a játék-leírásnak a hibája, hogy a kisbetűket nem teszi lehetővé az email-címben, de most ettől tekintsünk el!
Hogy a fejezet elején feltett 3) KÉRDÉS-re tudjunk válaszolni, meg kell vizsgálnunk, mi a különbség az internetes keresés és a könyvtári adatbázisban való keresés között.
Az előbb megkülönböztettünk tartalomindexelést, amit automatikusan végez a számítógép (vagyis az indexelő robotok) és kulcsszó-indexelést, amit a dokumentum létrehozója vagy rögzítője hajt végre. Alapvetően ez a különbség az internetes keresés és a könyvtári keresés között: az internetes dokumentumokon tartalomindexelés (is) fut, ami tokenizált, lemmatizált, parsolt adatokat jelent. A könyvtári adatbázisokban kulcsszó-indexelés, vagyis tárgyszavazás történik. Ilyenkor a rögzített könyvhöz a rögzítője tárgyszavakat rendel. Továbbá történik automatikus indexelés a főbb adatokról: cím, szerző neve, kiadó, de az esetek nagy részében nyelvtechnológiai eljárások nélkül.
Így megvan a válasz az utolsó kérdésre is, amivel a fejezetet indítottuk. Idézem:
„3. KÉRDÉS: Miért könnyebb az interneten pl. a Google segítségével megtalálni valamit, aminek nem tudjuk teljesen pontosan a címét vagy egyéb adatát, mint akár a szakkönyvtár keresőjében, akár egy oktatástámogató programban?„
Ha nem tudjuk pontosan a könyv címét (ahogy a 3. KÉRDÉSben nem ismertük Számítógéppel emberi nyelven c. könyv címét pontosan), akkor az a jó stratégia, ha minél rövidebb részletre keresünk a címből a könyvtári keresőben. A számítógép emberi nyelven rossz kereső-kifejezés, mert a könyvtári kereső nem tokenizálja, lemmatizálja az indexbe kerülő kifejezéseket, így csak a tárolt indexkifejezés egészére vagy töredékére lehet keresni. Töredéken azt értem, hogy az eleje vagy a vége hiányozhat. Pl. lett volna találat az emberi nyelven kereső-kifejezésre, de nem volt találat a A számítógép emberi nyelven kifejezésre, hiszen a tárolt adatokat nem lehetett karakterre pontosan a kereső-kifejezéssel azonosnak tekinteni.
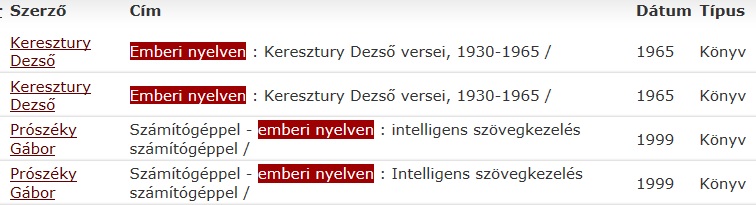
-
ábra: emberi nyelven kereső-kifejezés Forrás: könyvtári kereső.
A webes könyvesboltok a webes keresőkhöz hasonlóan tokenizálnak stb., ezért bennük a keresés jelentősen könnyebb, mint a könyvtári keresőkben.
19. FELADAT
Foglalja össze, milyen egyéb nehézségeket jelent(het) a felhasználóknak a könyvtári keresők használata! Segítségképpen olvassa el Viszket 2008b-t (http://vap.locsoft.hu/vap/szig_v05.pdf)!
Előfordult már Önnel is, hogy nem főneves kifejezésre keresett a weben, hanem természetes nyelvi kifejezést fogalmazott meg? Például: Mi Magyarország fővárosa?
20. FELADAT
Derítse ki az internet segítségével, hogy ki találta fel a gyufát! Milyen kereső-kifejezést használt?
A természetes nyelven feltett kérdésre csak akkor adható vissza megfelelő találati lista, ha a kérdést valamilyen, reguláris kifejezésekből és logikai operátorokból álló kereső-kifejezéssé tudjuk átalakítani. Például: Mi Magyarország fővárosa? = Magyarország NEAR főváros
Az átalakítás két módon történhet:
(1) A kérdést a kereső szavakra bontja, és a szavak együttes előfordulását keresi a dokumentumokban.
(2) Szintaktikai elemzéssel kikeresi a kérdésben szereplő főnévi csoportokat és ezekből rakja össze a logikai operátorokat tartalmazó kereső-kifejezést.
21. FELADAT
Még mindig Viszket 2008b-t (http://vap.locsoft.hu/vap/szig_v05.pdf) segítségével hasonlítsa össze két nyelvészeti portál keresőrendszerét: Nyelwww és Nyelvészet.hu!